Chi ben comincia è già a metà dell’opera
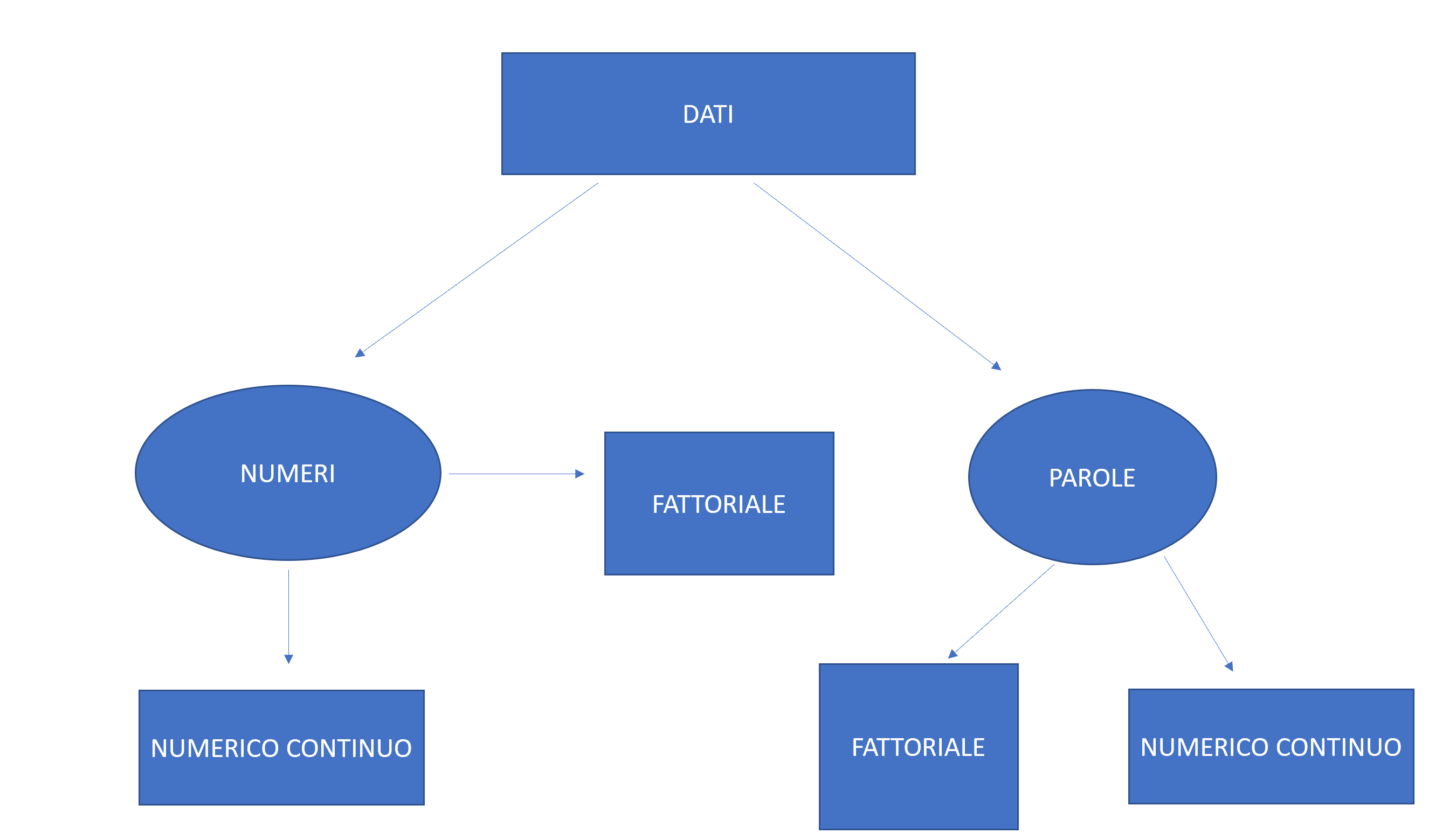
Se hai raccolto i tuoi dati ricordati che la qualità dei dati è importantissima per la tua analisi.
Prima di eseguire qualsiasi test o modello è necessario:
- Effettuare le statistiche descrittive
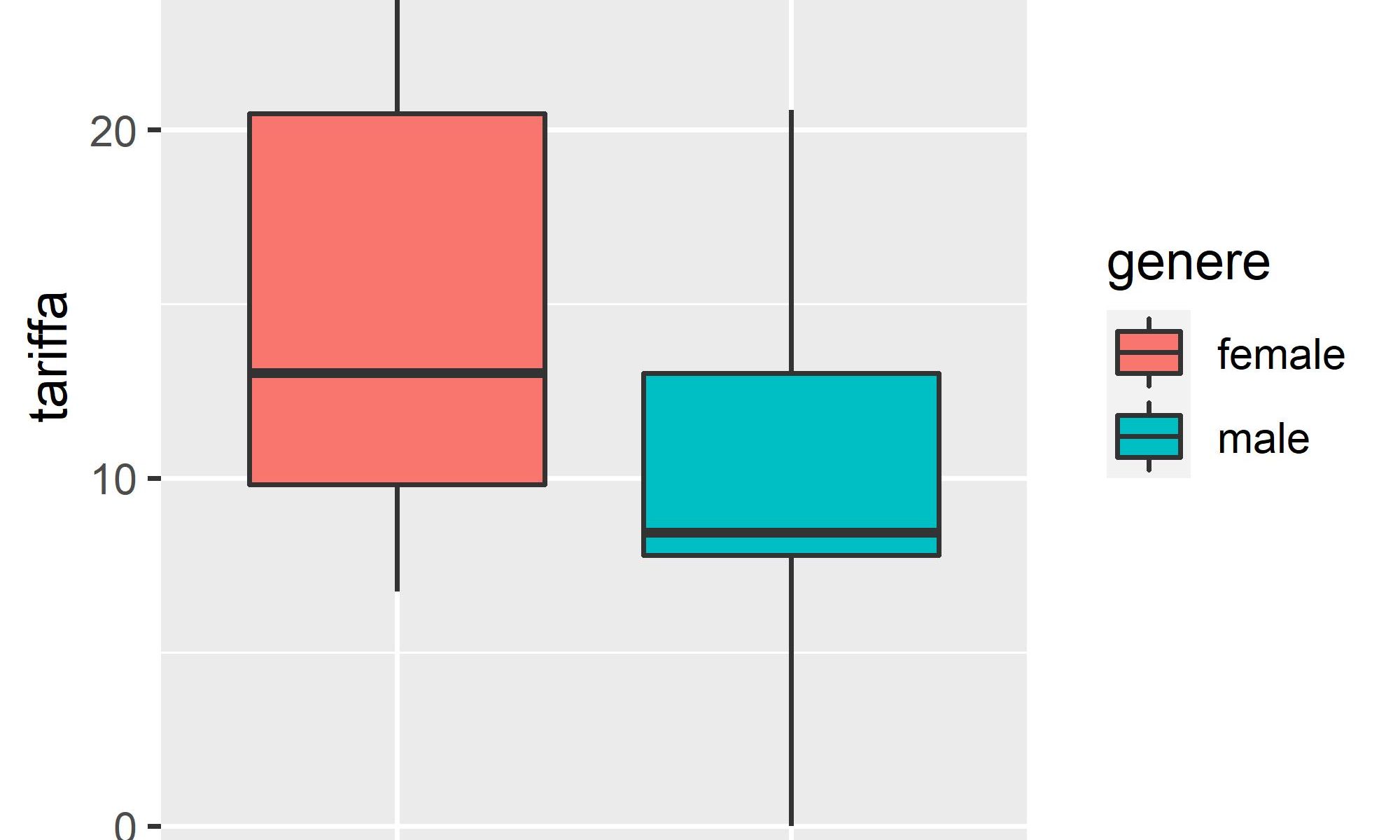
- Controllare gli outlier
- Comprendere dalle statistiche descrittive se vi sono problemi, come ad esempio degli NA (dati mancanti).
Se tutti questi 3 passi sono stati eseguiti correttamente, avrai dei dati che, statisticamente parlando, sono buoni per la analisi e avrai un idea, grazie alle statistiche descrittive, di come sia composto il tuo campione. Da ciò potrai formulare ipotesi da testare con i modelli o test.
Leggi tutto “3 passi fondamentali per la preparazione dei dati”